İlişkisel veritabanı
İlişkisel veritabanı, 1970 yılında Edgar Frank Codd tarafından önerildiği gibi, organizasyonu ilişkisel veri modeline dayanan bir dijital veritabanıdır.[1] İlişkisel veritabanlarını korumak için kullanılan çeşitli yazılım sistemleri bir ilişkisel veritabanı yönetim sistemi (RDBMS) olarak bilinir. Neredeyse tüm ilişkisel veritabanı sistemleri, sorgulama ve veritabanının bakımı için dil olarak SQL(Structured Query Language) kullanmaktadırlar.
İlişkisel model
Bu model, verileri her bir satırı tanımlayan benzersiz bir anahtarla sütunların ve satırların bir veya daha fazla tabloya (veya ilişkilere) düzenler. Satırlara kayıt veya "tuple" denir.[2] Genellikle, her tablo / ilişki bir varlık türünü (müşteri veya ürün gibi) temsil eder. Satırlar, o varlık türünün örneklerini ("Berk" veya "sandalye" gibi) ve bu örneğe atfedilen değerleri (adres veya fiyat gibi) temsil eden sütunları temsil eder.
Anahtarlar
Bir tablodaki her satırın kendine has ve benzersiz anahtarı vardır. Bir tablodaki satırlar, bağlantılı satırın benzersiz anahtarı için bir sütun ekleyerek diğer tablolardaki satırlara bağlanabilir(bu sütunlar yabancı anahtarlar olarak bilinir). Edgar Codd isteğe bağlı olarak karmaşıklığın veri ilişkilerinin basit bir kavramlar dizisi ile temsil edilebileceğini gösterdi.
Bu işlemin bir kısmı, bir tablodaki bir ve yalnızca bir satırı sürekli olarak seçebilmeyi veya değiştirmeyi içermektedir. Bu nedenle, çoğu fiziksel uygulamanın her tablo için benzersiz bir birincil anahtarı vardır. Tabloda yeni bir satır yazıldığında, birincil anahtarda (PK) yeni benzersiz bir değer oluşturulur.Sistemin öncelikli erişmek için kullandığı anahtar budur. Sistem performansı PK'ler için optimize edilmiştir.Buna ek olarak alternatif anahtarlar (AK) tanımlanabilir. Genellikle bir AK oluşturmak için birkaç sütun gerekebilir. PK'ler ve AK'ler, bir tablodaki bir satırı benzersiz şekilde tanımlama yeteneğine sahiptir. Dünyada benzersiz bir kimliği, küresel olarak benzersiz bir tanımlayıcı olan global güvenlik sağlayacak ek teknoloji uygulanabilir.Ancak bunlar daha geniş sistem gereksinimleri karşılandığında kullanılabilecektir.
Bir veritabanı içindeki birincil anahtarlar tablolar arasındaki ilişkileri tanımlamak için kullanılır. Bir PK başka bir tabloya taşındığında, diğer tabloda bir yabancı anahtar haline gelir. Her hücre yalnızca bir değer içerebilir ve PK, normal varlık tablosuna taşınırken, bu tasarım deseni bire-bir veya birden-çoğa ilişkiyi temsil edebilir. Çoğu ilişkisel veritabanı tasarımı, diğer varlık tablolarından gelen PK'leri içeren ek bir tablo oluşturarak çoktan çoklu ilişkiler kurar ve ilişki bir varlık haline gelir.Çözümleme tablosu daha sonra uygun şekilde adlandırılır.Ve sonuç olarak iki FK ve bir PK oluşturmak üzere birleştirilir.
İlişkiler
İlişkiler, farklı tablolar arasında mantıksal bir bağlantıdır. Bu alan tablolar arasındaki etkileşime dair bir ilişki kurulmasını ve düzenlenmesini kapsamaktadır.
İşlemler
Veritabanı yönetim sisteminin (DBMS) etkin ve doğru bir şekilde çalışması için ACID işlemlerine(Atomik yapı, tutarlılık, izolasyon, dayanıklılık) sahip olması gerekir.[3]
Saklı prosedürler
RDBMS içindeki programlama işlemlerinin çoğu saklı yordamlar(SP) kullanılarak gerçekleştirilir. Genellikle, bir sistemin içinde ve dışında aktarılan bilginin miktarını büyük ölçüde azaltmak için prosedürler kullanılabilir. Güvenliğin artması için, sistem tasarımı yalnızca tablolara değil saklı yordamlara da erişim düzenlemesi sağlayabilir. Temel saklı yordamlar, yeni veri eklemek ve mevcut verileri güncellemek için gerekli mantığı ve algoritmaları içerir. Verilerin işlenmesi veya seçilmesi ile ilgili ek kural ve mantıkların uygulanması için daha karmaşık prosedürler yazılabilir.
Terminoloji

İlişkisel veri tabanı ilk olarak Haziran 1970'de IBM'in San Jose Araştırma Laboratuvarının Edgar Codd tarafından tanımlandı.Codd'un RDBMS olarak nitelendirdiği şeyleri Codd'un 12 kuralında özetlemektedir.Böylelikle ilişkisel veritabanı en yaygın veritabanı türü haline geldi. İlişkisel modelin yanı sıra diğer modeller arasında hiyerarşik veritabanı modeli ve ağ modeli bulunur.
Aşağıdaki tablo, bazı önemli ilişkisel veritabanı terimlerini ve karşılık gelen SQL terimlerini özetlemektedir:
| SQL terimi | İlişkisel veritabanı terimi | Açıklaması |
|---|---|---|
| Satır | Veri seti veya kayıt | Bir veri setini temsil etmektedir ve tekil nesne olarak kabul edilir. |
| Sütun | Özellik veya alan | Veri setlerini içeren belirli bir etikettir.Örneğin: "adresler" veya "doğum tarihleri" gibi. |
| Tablo | Varlıklar arasındaki temel ilişki | Aynı öz nitelikleri paylaşan bir takım kümedir.Bir dizi satır ve sütundan oluşur. |
| Çıktı veya sonuç kümesi | Türetilmiş ya da kısıtlanmış biçimde veriler | Bir sorguya yanıt olarak elde edilmiş veri seti veya sorgudan gelen bir veri raporudur. |
İlişkiler veya tablolar
Bir ilişki, aynı özniteliklere sahip bir dizi kayıt(tuple) olarak tanımlanır. Bir grup genellikle bir nesneyi ve o nesne hakkındaki bilgileri temsil eder. Nesneler genellikle fiziksel nesneler veya kavramlardır. Bir ilişki genellikle satırlar ve sütunlar şeklinde düzenlenmiş bir tablo olarak tanımlanır. Bir öz nitelik tarafından başvurulan tüm veriler aynı etki alanındadır ve aynı kısıtlamalara uygundur.
İlişkisel model, bir ilişkiye ait verilerin özel bir düzene sahip olup olmadığını ve verilerin nitelikler üzerinde herhangi bir emir verip vermediklerini belirtir.Uygulamalar aracılığıyla sorgular belirtilerek verilere erişme, seçme, nitelikleri tanımlama, proje ve ilişkileri birleştirmek ve katılma gibi işlemler gerçekleştirilebilir.İlişkiler, "insert", "delete" ve "update" operatörlerini kullanarak değiştirilebilir. Yeni veri setleri açık değerler sağlayabilir veya bir sorgudan türetilebilir. Benzer şekilde, sorgular güncelleme veya silme için verileri tanımlar.
Her veri seti fiziksel alanda kapladığı yer gereği benzersizdir.Ancak yine de ilişkisel modelde, yalnızca, veri seti birincil anahtarsa kesin olarak benzersiz olduğu anlaşılır.Bununla birlikte, her bir satır için bir birincil anahtarın tanımlanması ya da kayıtlı bir grup olarak tanımlanmasına gerek yoktur.Çünkü bu yöntem tutarsızlığa sebep olmaktadır.
Temel ve türetilmiş ilişkiler
İlişkisel bir veritabanında, tüm veriler saklanır ve ilişkiler aracılığıyla erişilir. Verileri depolayan ilişkilere "taban ilişkileri" denir ve uygulamalarına "tablolar" denir. Diğer ilişkiler verileri saklamaz, ancak ilişkisel operasyonları diğer ilişkilere uygulayarak hesaplanmaktadır. Bu ilişkilere bazen "türetilmiş ilişkiler" denir. Uygulamalarda bunlara "sorgular" denir. Türemiş ilişkiler, çeşitli ilişkilerden bilgi almalarına rağmen tek bir ilişki şeklinde ifade edilebilmesi açısından oldukça elverişlidir. Ayrıca, türetilmiş ilişkiler bir soyutlama katmanı olarak kullanılabilir.
Etki Alanı
Bir alan, belirli bir öznitelik için olası değerlerin kümesini tanımlar ve öznitelik değerinde bir sınırlama olarak kabul edilebilir. Matematiksel olarak, bir alanı bir özniteliğe eklemek, öznitelik için herhangi bir değerin belirtilen kümedeki bir öge olması gerektiği anlamına gelir. Örneğin, "ABC" karakter dizisi tam sayı alanında değil, 123 tam sayısı değeridir. Alanın bir başka örneği "Cinsiyet" alanının olası değerleri ("Erkek," Kadın ") olarak tanımlar.Böylece" Cinsiyet "alanı (0.1) veya (E, K) gibi girdi değerlerini kabul etmez.
Kısıtlamalar
Kısıtlamalar bir niteliğin alan adını daha da kısıtlamayı mümkün kılar. Örneğin, bir kısıtlama belirli bir tam sayının özniteliğini 1 ile 10 arasındaki değerlere kısıtlayabilir. Kısıtlamalar, iş kurallarını veritabanında uygulamak için bir yöntem sağlar. SQL, denetim kısıtlamaları biçiminde kısıtlama işlevselliği uygular. Kısıtlamalar, ilişkilerde saklanabilecek verileri kısıtlar. Bunlar genellikle, bir boolean değeriyle sonuçlanan, verilerin kısıtlamayı karşılayıp karşılamadığını gösteren ifadeler kullanılarak tanımlanır. Kısıtlamalar, tek özniteliklere, bir veri setine veya bütün bir ilişkiye uygulanabilir. Her öznitelik ilişkili bir alan olduğundan, kısıtlamalara sahiptir(alan kısıtlamaları). İlişkisel model için iki ana kural, varlık bütünlüğü ve referans bütünlüğü olarak bilinir.
Birincil anahtar
Birincil anahtar, tablodaki bir takımı benzersiz olarak belirtir. Bir özniteliğin iyi birincil anahtarı olması için tekrar etmemesi gerekir. Doğal özellikler (girilen verileri tanımlamak için kullanılan özellikler) bazen iyi birincil anahtarlar olmakla birlikte, bunun yerine yedek anahtarlar kullanılır. Bir vekil anahtarı, onu benzersiz bir şekilde tanımlayan bir nesneye verilen yapay bir özelliktir (örneğin, bir okuldaki öğrenciler hakkında bir bilgi tablosunda, hepsini ayırt etmek için öğrenci kimliğine sahip olabilirler). Vekil anahtar kendine özgü bir anlam taşımayan, ancak bir kümeyi benzersiz şekilde tanımlama yeteneği sağlayan yararlı bir kullanımdır.Özellikle N: M kararlılığı açısından diğer yaygın kullanım ise, bileşik anahtardır. Bileşik anahtar, bir tabloda iki veya daha fazla öznitelikten oluşan ve birlikte kullanılarak bir kaydın benzersiz şekilde tanımlandığı bir anahtardır. (Örneğin, öğrenciler, öğretmenler ve sınıflar ile ilgili bir veritabanı verilsin.Sınıflar, derslik numaralarının ve eğitim döneminin birleşik bir anahtarı ile benzersiz olarak tanımlanabilir, çünkü başka hiçbir sınıf öznitelikleri tam olarak aynı kombinasyona sahip olamaz.) Her ne kadar bunun gibi birleşik bir anahtar, zayıf bir sistem olmasına rağmen, bir veri doğrulama biçimi olarak kullanılabilir.
Yabancı anahtar
Yabancı anahtar, ilişkisel tablodaki başka bir tablonun birincil anahtar sütunuyla eşleşen bir alandır. Yabancı anahtar, çapraz referans tabloları için kullanılabilir. Yabancı anahtarların, başvuru ilişkisinde benzersiz değerlere sahip olması gerekmez. Yabancı anahtarlar, başvurulan ilişkide bir veya daha fazla öznitelik alanını sınırlamak için başvurulan ilişkideki öznitelik değerlerini etkili biçimde kullanır. Bir yabancı anahtar, bilgisayar bilimi açısından olarak şöyle tanımlanabilir: "Bir tabloda yada ilişkide kullanılan bir anahtar alanı başka bir tabloda yada ilişkide yer alıyorsa, yani bir anahtar alanı başka bir anahtar alanını gösteriyorsa buna yabancı anahtar denir."
Saklı prosedürler
Saklı yordam, veritabanıyla ilişkilendirilen ve genellikle veritabanında saklanan yürütülebilir koddur. Saklı prosedürler genellikle ortak işlemleri (örn. Bir ilişkiye eklemek, kullanım modelleri hakkında istatistiksel bilgi toplamak veya karmaşık iş mantığını ve hesaplamalarını kapsüllemek gibi) toplamakta,özelleştirmekte ve standartlaştırmaktadır.Sıklıkla güvenlik veya basitlik için bir uygulama programlama arabirimi (API) olarak kullanılırlar. SQL RDBMS'lerdeki saklı yordamların uygulamaları genellikle geliştiricilerin standart bildirimsel SQL sözdizimine yordamsal uzantılardan (genellikle satıcıya özgü) yararlanmasına izin verir.Saklı yordamlar, ilişkisel veritabanı modelinin bir parçası değildir ancak tüm ticari uygulamalarda kullanılmaktadır.Özellikle bankacılık sektöründe yazılımcıların standart biçimde yazılım geliştirmesi ve koruması bu sayede olmaktadır.
İndeksleme
Bir dizin, verilere daha hızlı erişmenin bir yoludur. İndeksler, bir ilişki üzerinde herhangi bir öznitelik kombinasyonu üzerinde oluşturulabilir. Bu öznitelikleri kullanarak filtreleme yapılan sorgular, sırayla bütün veri seti için denetim yapmadan sadece eşleşen veri setlerini rastgele bulabilir. Bu yöntem, doğrudan aradığınız bilginin bulunduğu sayfaya gitmek için bir kitabın dizinini kullanmakla aynıdır.Dolayısıyla aradığınızı bulmak için kitabın tamamını okumamanıza benzer.İlişkisel veritabanlarında, genellikle birden fazla indeksleme tekniği bulunur; bunların her biri, veri dağılımı, ilişki boyutu ve tipik erişim modeli kombinasyonu için en iyisidir. İndeksler genellikle B+ ağaçları, R-ağaçları ve bitmap'ler vasıtasıyla uygulanır. İndeksler genellikle, veritabanının bir parçası olarak düşünülmez; çünkü bunlar, uygulama ayrıntısı olarak düşünülür.Ancak, indeksler genellikle veritabanının diğer kısımlarını koruyan aynı grup tarafından tutulur. Hem birincil hem de yabancı anahtarlar üzerinde etkili dizinler kullanılması sorgu performansını önemli ölçüde artırabilir. Bunun nedeni, B-tree indekslerinin sorgu sürelerinin log (n) ile orantılı olması ve n değerinin yalnızca bir tablodaki satırların sayısı olması ve hash indekslerinin sabit zaman sorgularıyla sonuçlanabilmesidir.
İlişkisel işlemler
İlişkisel veritabanında yapılan sorgular ve veritabanında türetilen ilişkiler bir ilişkisel hesap veya ilişkisel cebir olarak ifade edilir.Codd, has ilişkisel cebirde, her biri dört operatörden oluşan iki grupluk sekiz ilişkisel operatörünü tanıttı. İlk dört operatör, geleneksel matematiksel küme işlemlerine dayanıyordu:
Birlik operatörü, iki ilişkinin verilerini birleştirir ve tüm tekrarlanan verileri sonuçtan çıkarır. İlişkisel birleştirmede kullanılan komut "SQL UNION" komutuna eşdeğerdir.
Kesişme operatörü, iki ilişkinin ortak paylaştığı bir dizi veri üretir. Kesişme, "INTERSECT" biçiminde SQL'de uygulanmaktadır.
Fark operatörü iki ilişki üzerinde eğer ilk ilişkideki verilerden ikinci ilişkide bulunmayanlar bulunuyorsa çıktı üretir. SQL'de "EXCEPT" veya "MINUS" operatörü şeklinde uygulanır.
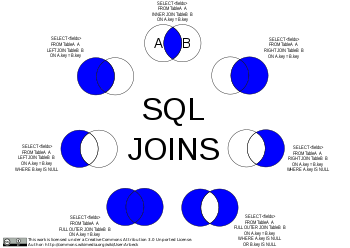
İki ilişkinin kartezyen çarpımı, herhangi bir ölçütle sınırlandırılmamış bir birleşmedir.Bu işlemde, ilk ilişkinin her bir birimi, ikinci ilişkinin her bir birimi ile eşleştirilir. Kartezyen ürün SQL'de "CROSS JOIN" operatörü olarak uygulanmaktadır.
Codd tarafından diğer önerilen operatörler, ilişkisel veritabanlarına ait bazı özel işlemleri içerir:
Seçim veya kısıtlama işlemi, bir ilişkiden verileri alır, sonuçları yalnızca belirli bir kriteri karşılayan örneklerle, yani küme teorisi açısından bir alt kümeyle sınırlar. Seçimin SQL karşılığı, "SELECT" sorgu deyimi yan tümcesi olan "WHERE" ifadesiyle birlikte kullanılır.
Projeksiyon işlemi, yalnızca bir veri veya veri kümesinde belirtilen öznitelikleri ayıklar.
İlişkisel veritabanlarında tanımlanan birleştirme işlemi genellikle doğal katılma olarak adlandırılır. Bu tür birleşimlerde, iki ilişki ortak özellikleriyle birleştirilir. MySQL'in doğal katılma yaklaşımı INNER JOIN operatörüdür. SQL'de INNER JOIN, bir sorgudaki iki tablo olduğunda bir kartezyen ürünün oluşmasını önler. Bir SQL sorgusuna eklenen her tablo için oluşan kartezyen ürünü önlemek için bir başka INNER JOIN eklenir. Dolayısıyla, bir SQL sorgusundaki N tablolar için, kartezyen bir ürünü önlemek için N-1 tane "INNER JOINS" olmalıdır.
İlişkisel bölme işlemi biraz daha karmaşık bir işlemdir ve esasen bir ilişkinin (yada tablonun) verilerini ikinci bir ilişkiyi bölmek için kullanma işlemidir.İlişkisel bölme operatörü kartezyen çarpım işlemcisinin tam tersidir.
Codd'un sekiz tane has ilişkisel cebir işlemini tanıtmasından bu yana, diğer operatörler; ilişkisel karşılaştırma operatörleri, iç içe yerleştirme ve hiyerarşik veriler için destek sunan eklentiler de dahil olmak üzere sunuldu.
Normalizasyon
Normalleştirme ilk önce Codd tarafından, ilişkisel modelin ayrılmaz bir parçası olarak önerildi. Basitleştirilmemiş alanları(atomik olmayan değerler) ve gereksiz veri fazlalılığını ortadan kaldırmak için tasarlanmış bir dizi yordamı kapsamaktadır.Bu da, veri işlemeyi normalleştirir ve veri bütünlüğü sağlar.Veritabanlarına uygulanan en yaygın normalleştirme biçimleri normal formlar olarak adlandırılır.
Dağıtık ilişkisel veritabanları
Dağıtık İlişkisel Veritabanı Mimarisi (DRDA) 1988-1994 döneminde IBM içinde bir çalışma grubu tarafından tasarlanmıştır. DRDA, ağa bağlı ilişkisel veritabanlarının SQL taleplerini yerine getirmek için entegre çalışmasını sağlar.[4] DRDA'nın mesajları, protokolleri ve yapısal bileşenleri Dağıtık Veri Yönetimi Mimarisi(DDMA) tarafından tanımlanır.
Kaynakça
- ↑ a b Codd, E.F. (1970). "A Relational Model of Data for Large Shared Data Banks". Communications of the ACM. 13 (6): 377–387. doi:10.1145/362384.362685.
- ↑ "A Relational Database Overview". oracle.com.
- ↑ "Gray to be Honored With A. M. Turing Award This Spring". Microsoft PressPass. 1998-11-23. Archived from the original on 6 February 2009. Retrieved 2009-01-16.
- ↑ Reinsch, R. (1988). "Distributed database for SAA". IBM Systems Journal. 27 (3): 362–389. doi:10.1147/sj.273.0362..